How Google Search Engines Work: The Truth Behind Google’s Complex Architecture
The SEO world is drowning in misinformation. While everyone obsesses over the latest “ranking hacks,” most professionals completely misunderstand the fundamental systems that power search engines like Google. This isn’t just academic knowledge—it’s the foundation that separates true SEO experts from those who panic with every algorithm update.
After spending over a decade studying Google’s architecture and research papers, I’ve witnessed countless SEOs make the same critical mistake: they focus on tactics without understanding the underlying machine. This deep dive will change how you think about search engines forever.
Why Understanding Search Engine Architecture Matters More Than Ever
The SEO landscape is experiencing unprecedented anxiety. ChatGPT and other AI tools have sparked fears about Google’s relevance and the future of traditional search. But here’s the uncomfortable truth: most of these fears stem from a fundamental misunderstanding of how search engines and language models actually work.
Google’s search engine and ChatGPT operate on completely different principles. One crawls, indexes, and retrieves information from the web. The other generates responses based on training data. They’re not competitors—they’re different tools for different purposes. Understanding this distinction isn’t just academic; it’s essential for your professional survival.
When you truly grasp how Google’s systems function, algorithm updates become predictable rather than terrifying. You stop chasing rumors and start making data-driven decisions based on how the machine actually works.
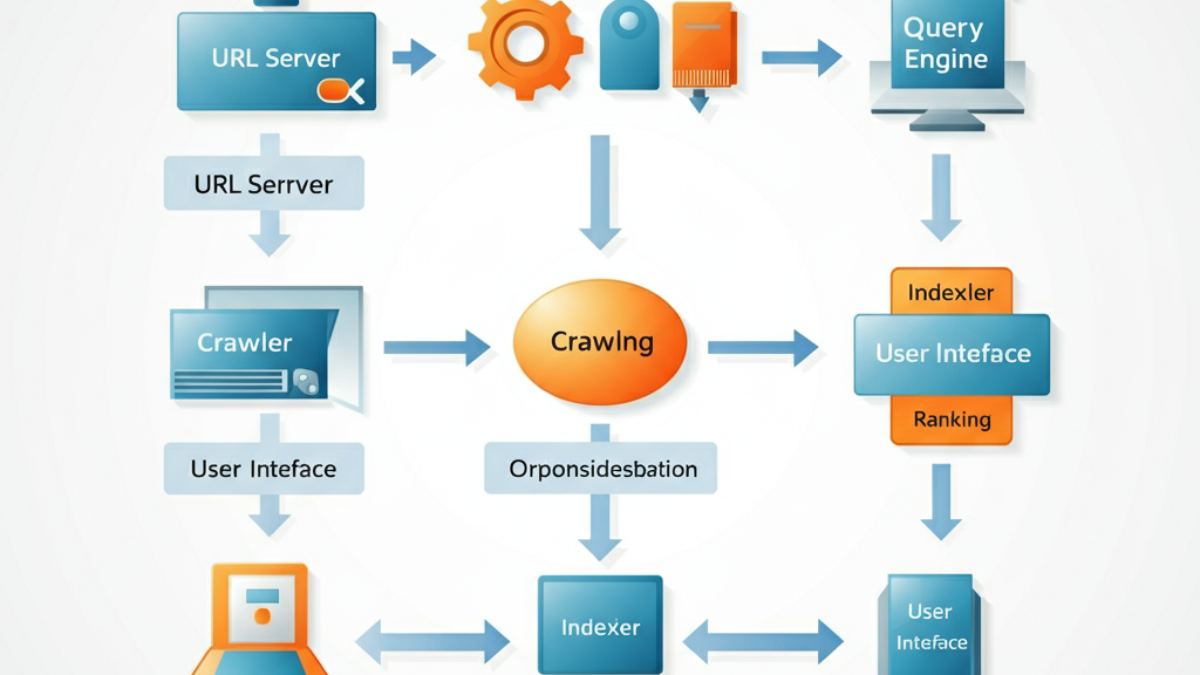
The Simple Search Engine: Understanding the Basics
Before diving into Google’s complexity, let’s establish the foundation. Every search engine follows a basic pattern that consists of five core components:
- The Internet – The source of all content
- Crawler – Programs that visit websites and collect data
- Indexer – Systems that process and organize the collected data
- Index – The storage system for processed information
- Query Engine – The interface between users and the stored data
This simplified model shows a linear flow: content flows from the internet through multiple processing layers before reaching users. The key insight here is that your content doesn’t go directly from your website to search results—it travels through multiple systems, each with its own processing requirements and potential bottlenecks.
Why Your Website Isn’t Getting Indexed: The Real Reason
Many website owners grow frustrated when their content doesn’t appear in search results immediately. They publish content and expect instant visibility. But as the architecture shows, indexing is not a simple, direct process. Your content must successfully pass through multiple systems:
- The crawler must successfully visit your page
- The store server must compress and save your content
- The indexer must process your content into searchable components
- The index must store the processed information
Each step introduces potential delays or failures. Understanding this pipeline helps set realistic expectations and identify where problems might occur.
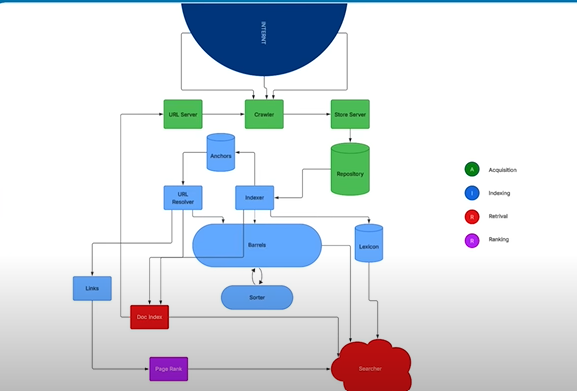
Google’s Complex Reality: A Deep Dive Into Modern Search Architecture
Google’s actual architecture is exponentially more complex than the basic model. The modern Google search system operates through approximately 12 interconnected nodes, each serving specific functions within four primary categories:
| Processing Stage | Function | Key Systems |
|---|---|---|
| Acquisition | Gathering content from the web | URL Server, Crawler |
| Indexing | Processing and organizing content | Indexer, Store Server, Repository |
| Retrieval | Finding relevant content for queries | Barrel, Sorter, Lexicon |
| Ranking | Determining result order | PageRank, Document Index |
This complexity isn’t accidental—it’s designed for scalability, efficiency, and reliability. Each system can be upgraded, scaled, or optimized independently without disrupting the entire search engine.
The URL Discovery Revolution: 10 Methods Google Uses (Not Just Sitemaps)
Most SEOs obsess over XML sitemaps, but Google actually uses 10 different methods to discover URLs. This revelation fundamentally changes how you should approach content discovery:
Primary Discovery Methods
- XML Sitemaps – The traditional method most SEOs know
- Internal Links – Links from one page on your site to another
- External Links – Links from other websites to yours
- Intelligent URL Guessing – Google predicts URL patterns
Advanced Discovery Systems
- Server Log Analysis – Google analyzes server error logs for URL patterns
- Chrome Browser Data – URLs visited in Chrome browsers
- Domain Registration Monitoring – Google tracks newly registered domains
- RSS Feed Monitoring – Content feeds provide URL discovery
- Google Search Console Submissions – Manual URL submission requests
- JavaScript Rendering – URLs discovered through dynamic content
The Strategic Implication: Don’t rely solely on sitemaps. A comprehensive URL discovery strategy should leverage multiple methods. For example, if you create pages numbered 121, 122, 123, and 125, Google will automatically attempt to find page 124 through intelligent guessing.
The Journey of Content: From Web Page to Search Result
Understanding the complete journey of your content through Google’s systems reveals optimization opportunities most SEOs miss:
Phase 1: URL Discovery and Initial Processing
The journey begins at the URL Server, which maintains massive lists of URLs and feeds them to crawlers in batches. This system removes duplicates and prioritizes URLs based on source and urgency. URLs submitted through Google Search Console receive priority processing.
Phase 2: Crawling and Storage
Google’s Crawler (Googlebot) visits URLs using a headless version of Chrome. It downloads HTML, images, videos, and other assets, attempting to render pages exactly as users would see them. The crawler doesn’t analyze content—it simply collects and saves everything.
The Store Server compresses this data and assigns internal IDs. Think of it as creating a zip file for each page, which then gets stored in Google’s massive Repository—essentially a backup of the entire internet.
Phase 3: Content Analysis and Processing
The Indexer performs two critical functions:
Hit Generation: Breaking down page content into individual words or word groups, assigning each a unique Word ID. Every word’s position, font size, color, and capitalization gets recorded in what Google calls a “HIT.”
Link Extraction: Identifying and extracting all links and their anchor text for further processing.
Phase 4: System Distribution
From the indexer, content flows to multiple specialized systems:
- Anchors: Stores link anchor text
- URL Resolver: Converts relative URLs to absolute URLs and manages document IDs
- Links: Creates maps of all internet link relationships
- Document Index: Creates quick-lookup versions of pages for fast retrieval
The Search Process: How Queries Become Results
When users search, their queries don’t go directly to Google’s massive index. Instead, they interact with the Searcher system, which coordinates with multiple components:
- Query Processing: The Lexicon system breaks down search queries into Word IDs, matching them against known terms
- Content Retrieval: The Barrel system provides forward and reverse indexes of content
- Link Analysis: PageRank calculates the authority and relevance of pages
- Result Compilation: Multiple systems contribute information for final ranking
Critical Insight: Google doesn’t pre-rank all pages and store those rankings. Instead, ranking happens in real-time when you search. The system first determines which pages are relevant, then applies ranking signals to determine their order.
The PageRank Reality: Why Links Still Matter (But Not How You Think)
PageRank receives input from the Links system, which maps every link relationship on the internet. However, the final search results incorporate information from four different systems, not just PageRank:
- PageRank (link authority)
- Document Index (content relevance)
- Barrel System (content matching)
- Lexicon (query understanding)
This is why Google representatives often say “don’t focus solely on links”—they’re only one input among many. Modern SEO requires understanding all systems, not just link building.
Practical Implications for Modern SEO
Content Discovery Optimization
Instead of relying solely on XML sitemaps:
- Create strong internal linking structures to help Google discover content naturally
- Use complete, absolute URLs rather than relative URLs to reduce Google’s processing load
- Monitor your server logs for crawling patterns and errors
- Submit important URLs directly through Google Search Console for priority processing
Technical SEO Fundamentals
- Ensure proper rendering: Since Google uses a headless Chrome browser, test your pages with similar tools
- Optimize for compression: Google compresses your content—larger pages require more processing resources
- Structure content clearly: The HIT generation process works better with well-structured content
- Use semantic markup: Help Google’s systems understand your content relationships
Content Strategy Evolution
Understanding Google’s architecture reveals why certain content strategies succeed:
- Topic clustering works because it strengthens internal linking and helps the Links system map relationships
- Content freshness matters because the URL Server prioritizes recently discovered or updated URLs
- User experience signals are crucial because they influence the Document Index’s quick-lookup data
The Future: Preparing for AI Integration
Google is integrating AI into its search systems, but this doesn’t replace the fundamental architecture—it enhances it. The core processes of crawling, indexing, and retrieval remain essential. AI adds layers of understanding and personalization on top of this foundation.
Key preparation strategies:
- Focus on content quality and depth – AI systems excel at understanding comprehensive, authoritative content
- Optimize for semantic search – Create content that answers questions thoroughly, not just targets keywords
- Build topical authority – Develop expertise in specific subject areas rather than trying to rank for everything
- Maintain technical excellence – The fundamental systems still require properly crawlable, indexable content
Common Misconceptions Debunked
“Google Has 200 Ranking Factors”
This number was essentially marketing fiction. While Google uses multiple signals, focusing on 5-6 primary factors will yield better results than trying to optimize for an arbitrary number of signals.
“SEO Is Dead Because of AI”
This fear reveals a misunderstanding of both search engines and AI. Google’s architecture is designed for web content discovery and retrieval. AI tools like ChatGPT generate responses from training data. They serve different purposes and will likely coexist.
“Algorithm Updates Are Unpredictable”
When you understand the underlying systems, updates become more logical. Most updates refine existing processes rather than introducing entirely new concepts.
Actionable Next Steps
- Audit your URL discovery strategy: Ensure you’re leveraging multiple discovery methods, not just XML sitemaps
- Analyze your internal linking: Create clear pathways for both users and crawlers
- Monitor your technical implementation: Use tools that simulate Google’s crawling and rendering process
- Focus on comprehensive content: Create resources that thoroughly address user needs
- Study Google’s research papers: Stay informed about actual system developments rather than speculation
Conclusion: Knowledge as Competitive Advantage
The SEO industry is full of surface-level tactics and anxiety-driven speculation. True competitive advantage comes from understanding the fundamental systems that power search engines. When you grasp how Google’s architecture actually works, you make better decisions, create more effective strategies, and maintain confidence during industry turbulence.
This knowledge isn’t just academic—it’s practical power. Every technical decision, content strategy, and optimization effort becomes more effective when guided by actual understanding rather than best-practice guesswork.
The professionals who thrive in the evolving search landscape won’t be those with the most tactics—they’ll be those who understand the machine well enough to adapt to any change. The question isn’t whether search engines will evolve; it’s whether you’ll understand them well enough to evolve with them.
The next time someone panics about an algorithm update or declares “SEO is dead,” you’ll have something most professionals lack: actual knowledge of how the system works. That knowledge is your competitive advantage in an industry built on speculation and fear.